在读这篇博客之前……
当然是需要一点点 Python 语法基础,Windows 的用户需要手动安装一下 Python 环境,还有一些计算机网络原理的基础,例如是 HTTP 协议之类的。
此外,最好还会使用 Chrome 的 Inspect 功能,因为我会用这个工具去分析整个教务系统的前后端是如何运行的。
最后,还需要会解决 Python 各种包安装的问题,使用 pip 或者源码安装,下面会用到 urllib、cookielib、PIL、pytesser 和 json 几个库。
最后的最后,本博客仅对 Web 开发,Python 开发进行探讨,进行实验时请遵守学校的规章制度。
前言
很多人有误区,以为抢课脚本就是像游戏外挂一样,利用什么系统漏洞去搞到课,而事实上抢课脚本只是模拟浏览器和服务器进行交互而已。而它们之间交互的方式是使用 HTTP 协议,换言之你的程序只要通过 HTTP 协议与服务器进行交互,就可以模拟浏览器能完成的事情。
当然,最朴素的抢课脚本应当数按键精灵,滔神的最爱。但是按键精灵依赖于浏览器的渲染速度,而使用 HTTP 协议交互的脚本可以忽略一切 CSS JS 文件的解析,直接发请求,资源占用和速度都优化了一个量级,而且可以丢在服务器或者树莓派上跑,有结果之后通过微信或者邮件通知用户即可。
Cookies
因为 HTTP 协议是无状态的,即服务器不知道用户上一次做了什么,这严重阻碍了交互式 Web 应用程序的实现。在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两饮料。最后结帐时,由于 HTTP 的无状态性,不通过额外的手段,服务器并不知道用户到底买了什么。 所以 Cookie 就是用来绕开HTTP的无状态性的“额外手段”之一。服务器可以设置或读取 Cookies 中包含信息,借此维护用户跟服务器会话中的状态。
在刚才的购物场景中,当用户选购了第一项商品,服务器在向用户发送网页的同时,还发送了一段 Cookie,记录着那项商品的信息。当用户访问另一个页面,浏览器会把 Cookie 发送给服务器,于是服务器知道他之前选购了什么。用户继续选购饮料,服务器就在原来那段 Cookie 里追加新的商品信息。结帐时,服务器读取发送来的 Cookie 就行了。
Cookie 另一个典型的应用是当登录一个网站时,网站往往会请求用户输入用户名和密码,并且用户可以勾选“下次自动登录”。如果勾选了,那么下次访问同一网站时嗯额,用户会发现没输入用户名和密码就已经登录了。这正是因为前一次登录时,服务器发送了包含登录凭据(用户名加密码的某种加密形式)的 Cookie 到用户的硬盘上。第二次登录时,(如果该 Cookie 尚未到期)浏览器会发送该 Cookie,服务器验证凭据,于是不必输入用户名和密码就让用户登录了。
Reference: Cookie - 维基百科,自由的百科全书
简而言之,由于 HTTP 是无状态协议,所以每次提交请求,服务器无法判断你是否是之前的用户,因此在动态网页中常用 Cookies 来鉴别用户身份,Cookies 是附加在每次 HTTP 请求中用来识别用户身份的数据。
在 Python 中,直接使用 urllib2 默认的 urlopen 是不能处理好 Cookies 的,这里的 urlopen 可以看成是一个能向目标 URL 发请求的对象。所以我们使用 cookielib 来构造一个能处理 Cookies 的 opener。
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
以后,我们使用 opener.open(url) 就可以带 Cookies 去发 GET 请求了。
登录
首先用 Chrome 分析一下教务系统的逻辑是怎样的,打开 Inspect 然后打开 http://uems.sysu.edu.cn/elect。
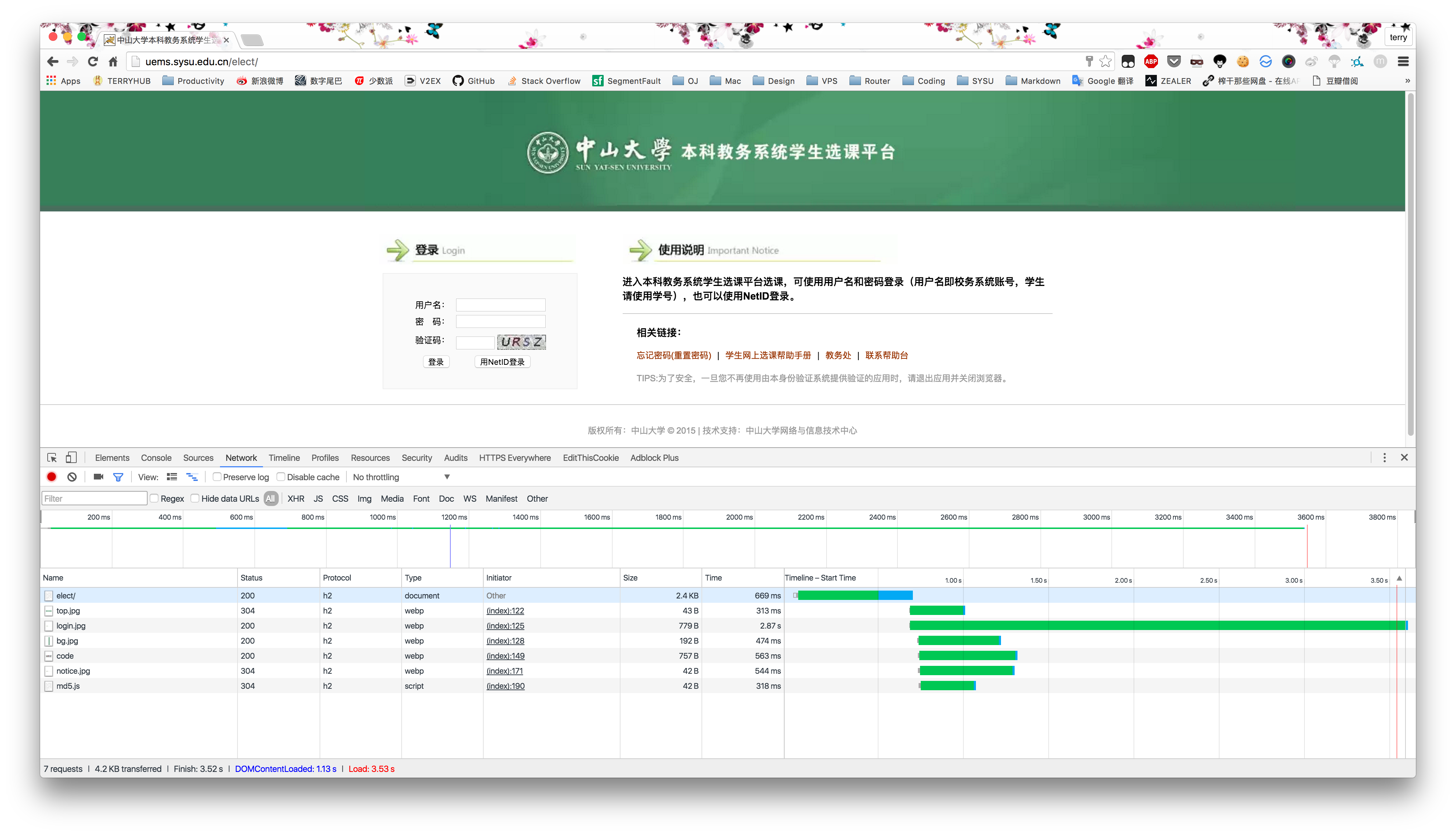
可以看出,前端很简洁,而且从文件名可以简单地看出 code 应该是验证码的请求,md5.js 应该是散列函数,应该是处理密码用的。
然后我们手动登录一下,看看登录的请求是怎样的。
可以看出发送了一个 POST 请求,请求地址是 http://uems.sysu.edu.cn/elect/login。表单内容有 username、password、j_code 和一堆不知道含义的东西。显然 username 是学号了,password 有经验的可以看出来是的 MD5 散列之后的结果,j_code 是验证码结果。
直接对应填上即可。
post_data = {}
post_data['username'] = username
post_data['password'] = pasw_md5
post_data['j_code'] = captachaCode
post_data['lt'] = ''
post_data['_eventId'] = 'submit'
post_data['gateway'] = 'true'
post_data = urllib.urlencode(post_data)
opener.open(login_url, post_data)
验证码
这里有一个问题,验证码当然可以人工输入,但是瞄了一样教务系统的验证码加的噪声也太少了,好歹也是学过树莓 (Digital Media Processing) 的人,能不能让计算机自己识别?关于验证码这里,有一篇是 Joen Hune 同学写的 OpenCV 完成的验证码识别,大家可以过去膜拜一下。
由于树莓课没有好好认真听,额,是没怎么去上,我就只能面向 GitHub 编程了。
最后我选择利用 pytesser 模块中的 image_to_string 函数进行 OCR 识别。但在这之前,需要对黑边进行裁切,再进行识别。
w, h = img.size
img = img.crop((1, 1, w-1, h-1))
captachaCode = image_to_string(img)
经测试下来准确率大概是 70 %,既然有失败的可能,我们就让它失败自动重试好了。
这样综合下来,验证码识别的代码是这样的。
captachaCode = ''
while captachaCode == '':
opener.open(main_url)
captacha_pic = Image.open(opener.open(captacha_url))
img = Image.open(opener.open(captacha_url))
w, h = img.size
img = img.crop((1, 1, w-1, h-1))
captachaCode = image_to_string(img)
captachaCode = captachaCode.replace(' ', '')
MD5
既然知道了和 MD5 有关系,可以用 Python 的 md5 模块进行尝试。
pasw_md5 = md5.new()
pasw_md5.update(password)
pasw_md5 = pasw_md5.hexdigest().upper()
一测试发现,提交的就是密码的 MD5 散列,问题就轻易解决了。当然如果不对,一般来说可以尝试用户名+密码的组合,还有是加上时间戳的组合,最后不行就去逆向 JS 文件吧。
SID
一般来说,登录之后,我们需要观察网站是如何维持一个 SESSION 的,一般来说维持 Cookies 即可,但观察到每次访问的 URL 总带上一个参数。例如 http://uems.sysu.edu.cn/elect/s/types?sid=a4b5d707-0a50-442e-b2d3-b5f947ea4401 就带着一个 sid。我们可以尝试去掉这个 sid 看看是否有影响。

可以看到 SESSION 已经失效,证明这个 SID 是维护这个 SESSION 必须的。所以以后每次请求必须带上这个 SID。
然后我们这里看到,登录后是通过 302 redirect 这个状态码跳转的,之后这个参数是写死在 HTML 的 <a href=""></a> 标签里面的,所以我们直接可以通过响应进行提取。
response = opener.open(login_url, post_data)
requestUrl = urlparse.urlparse(response.geturl())
request = urlparse.parse_qs(requestUrl.query)
sid = request['sid'][0]
抢课请求
相信到这里很多人已经摸到套路了,无非就是抓一个请求,分析,然后伪造这个请求。
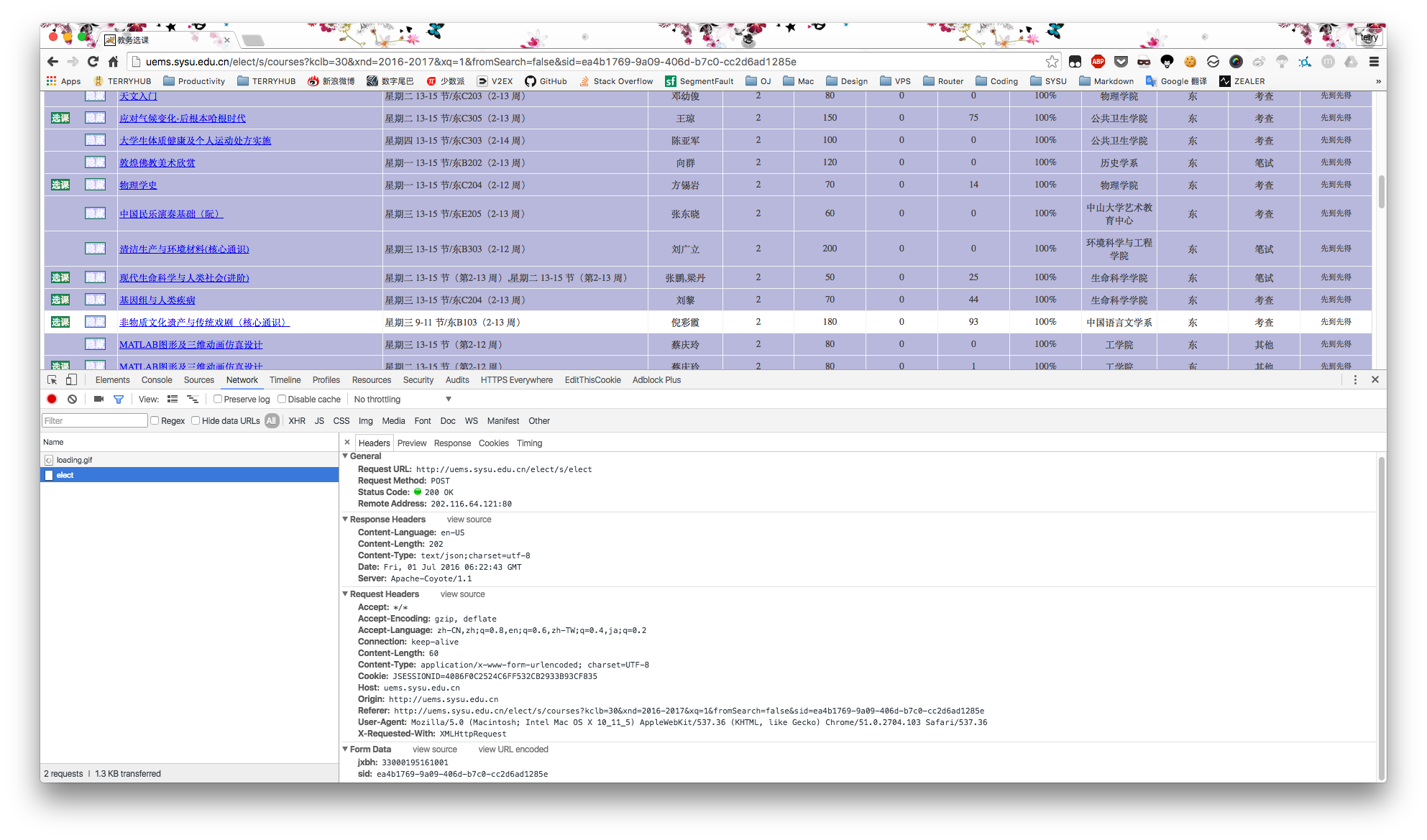
这里发现选课只需要发一个 POST 请求到 http://uems.sysu.edu.cn/elect/s/elect,当然也有带上 SID,此外还有一个参数,想必就是课程编号了。
和登录一样,我们构造一个字典,然后用 urllib 中的 urlencode 功能进行编码,最后使用 opener.open(res, elect_post_data) 发送请求即可。
elect_post_data = {};
elect_post_data['sid'] = sid
elect_post_data['jxbh'] = jxbh
res = urllib2.Request(elect_url)
opener.open(res, elect_post_data)
如果再套上一个死循环,这个抢课脚本就写完了。当然,肯定是有很多问题的,我们慢慢来解决。
Delay
如果直接死循环而不加上延时,服务器多半会挂掉。因为客户端的一个请求对应服务器的一次数据库查询,多半这样的压力学校服务器是受不了的。而且过高的发包很容易被查水表,一般来说 0.5s 到 0.3s 的延时已经足够超越极大部分单身二十年少年的手速。
浏览器伪装
一般的 Web 都是会对 HTTP 的请求头进行检测,以防止一些最简单的爬虫,很幸运的是,教务系统并没有。但是一旦对方的 Web Server 开启了访问记录,很容易把这些 HTTP 请求头为空的请求筛选出来,然后慢慢查水表之类的,所以为了安全起见,我们需要伪造浏览器的请求头。
UA = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
Referer = 'http://uems.sysu.edu.cn/elect/s/courses?kclb=21&xnd=2016-2017&xq=1&fromSearch=false&sid=' + sid
X_Requested_With = 'XMLHttpRequest'
res.add_header('User-Agent', UA)
res.add_header('Referer', Referer)
res.add_header('X_Requested_With', X_Requested_With)
异常处理
这个是写软件的基本功了,一般的 I/O 操作都需要异常处理,防止失败导致的程序崩溃,在 HTTP 请求中会有两种异常,第一是服务器返回非 2 开头的状态码,例如是 500 服务器错误,请求不知道有没有完成;另外就是更加底层的,不能建立 TCP 连接,包括但不限于 DNS 查找失败,TCP 连接超时等。
try:
res = urllib2.Request(elect_url)
response_content = opener.open(res, elect_post_data).read()
except urllib2.HTTPError as e:
print e
except BaseException as e:
print 'Unknow Error.'
解析响应
上面的代码我们只处理了发送请求,而并没有理会响应,这样即使抢到了课,程序还是会继续运行下去。
我们先分析一下响应是怎样的,Chrome 中 Inspect 有一个很好用的功能是 Copy as cURL,可以将这次请求提取为 cURL 命令,方便丢到命令行进行分析。


可以看出这是一个 JSON 格式的响应,在 Python 处理 JSON 很方便,我们可以用 json 库中的 response_json = json.loads(response) 将 JSON 字符串转换为一个字典。这样你就可以根据响应来后续处理,例如是微信通知之类的。
仅仅是抢课而已?
上面简述了一个抢课脚本的原理,当然不限于抢课,你可以写一个换课脚本,只需要两个 opener 即可模拟两个浏览器,这样可以最大限度地防止你的课被抢走。
此外,前段时间我在写一个解析教务系统的课程表,并导出 ics 格式的脚本,能轻易将大量的课程导入到电脑的日程管理软件中,现在这个脚本已经进入收尾阶段了。只不过正则写得太丑,不好意思拿出来而已。
Web 挺好玩的。